News & press releases
CLASS Data Analytics workflow: Approaching the final deployment stage
As we are approaching the final deployment and demonstration of the CLASS use cases at the city of Modena, we have been working on mapping the CLASS data analytics workflow onto the available computing infrastructure at the Modena Automotive Smart Area (MASA). In the figure below, we present an example of how the different data analytics methods can be distributed across the compute continuum.
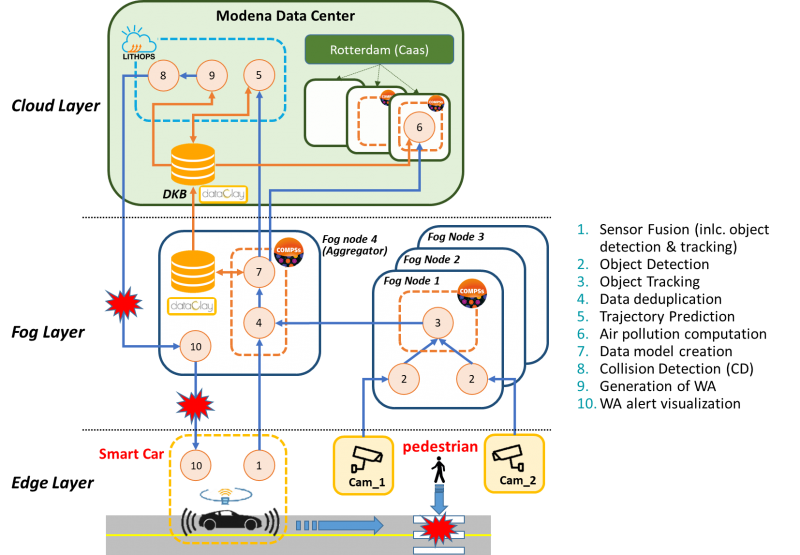
As shown in the figure, the computation takes place in three layers, i.e., edge, fog and cloud. The main components of each layer are described next.
The edge layer consists of a network of cameras covering the MASA area, and a small fleet of smart cars equipped with LIDAR, GPS, and cameras, provided by the CLASS partner Maserati. Additionally, some connected cars are also available, which can communicate their GPS position and receive alerts, but do not include any additional sensing devices.
The fog layer consists of four computing nodes, dedicated to process in a distributed way the information coming from the edge node, aggregate them and federate them to the cloud. The COMPSs framework is employed for the distribution of the real-time data analytics methods at the fog layer. The COMPSs orchestrator is responsible for selecting in runtime the most appropriate location for the execution of the different computation tasks, which can be executed at any of the four fog nodes where COMPSs workers are deployed (marked as orange dotted boxes).
Finally, the cloud layer provides the necessary computing infrastructure to host the Distributed Knowledge Database (DKB), where all the real-time information obtained by the CLASS data analytics is stored, and to execute heavy computational data analytics methods. The lightweight serverless framework Lithops is used to accelerate computation by supporting concurrency. Furthermore, Rotterdam is employed as a Container-as-a-Service (CaaS) layer, to facilitate the deployment and lifecycle management of containerized applications, providing additional resources to COMPSs workflows on-the-fly.
In continuation, we describe the main methods of the CLASS data analytics workflow.
As a first step, the detection of objects captured by the edge sensing devices is performed. In particular, a sensor fusion algorithm (method 1) is employed at the smart cars, to combine the input of all the available sensors (e.g., LiDAR and cameras) and detect and track any objects surrounding the car. At the street level, live video streams are obtained by street cameras and processed at the fog nodes. Once the object detection (method 2) returns the detected objects and their type (e.g., car, pedestrian, cyclist, etc.), the object movement is tracked by the object tracking algorithm (method 3), which computes additional information such as the history of the object positions as it moves, its speed and direction. The information of all the detected and tracked objects by both the cameras and the smart cars are collected by the aggregator fog node and fed into the deduplicator (method 4). The deduplication method is responsible of merging multiple detections of the same object by different sources into a single object and making sure that the same object is correctly identified as it moves into the coverage area of different cameras. The deduplicated object information is then injected into the CLASS data model (method 7) which is first locally stored at the fog layer and then federated to the cloud, to the Distributed Knowledge Database (DKB).
The information available in the DKB is leveraged by two different CLASS use cases. On one hand, it is fed into an air pollution computation method (method 6), which is able to calculate in real-time an estimation of the vehicle-related emissions based on the speed and acceleration of the detected vehicles at street level.
On the other hand, the DBK data is used for the obstacle detection application which predicts potential collisions and promptly alerts the involved smart or connected cars. Whenever a moving object is inserted or updated (with a newer detected position) in the DKB, the trajectory prediction algorithm (method 5) provides an estimation of its course for the next few seconds. Based on this updated information stored in the DKB, the potential collisions can be estimated for each smart and connected vehicle in the following way. First, for each connected car, the warning area is generated (method 9), defined as the area around the vehicle where the presence of hazards is relevant. Then, the collision prediction (method 8) is periodically invoked, to estimate the risk of collision based on the predicted trajectories of the connected car and all the objects present in its warning area. Finally, for all the identified potential collisions, an alert is generated (method 10) and is forwarded to the respective connected cars through the LTE network.